


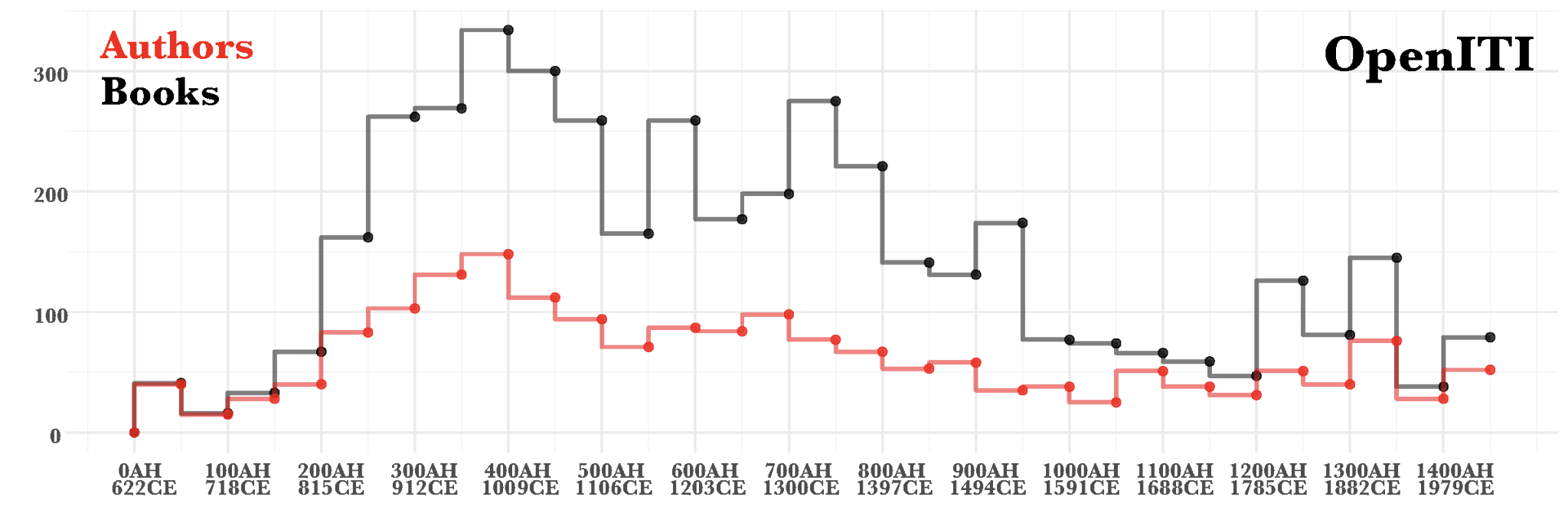
The OpenITI corpus is a open-access and machine-actionable collection of Persian and Arabic texts.
The large number of texts in our collection are in various stages of being transformed into standards-compliant and metadata-enriched scholarly corpus texts.
Most OpenITI corpus texts are built upon digital texts we obtained from Shamilah, al-Jāmiʿ al-Kabīr, Maktabat al-Shiʿa, Ganjoor, and other online collections that have varying levels of fidelity to the original print versions (due to manual or automatic—i.e., OCR—transcription errors). In the coming years, however, we will be dramatically scaling up the number of new digital texts that we add to the corpus through our own OCR process developed in the OpenITI AOCP project.
For more information on the OpenITI corpus, please see here, and here.
For more information on OpenITI’s work on digital publications, please see its project page.