


There are any number of reasons a researcher might want to transcribe a digitized manuscript, and there are now a number of tools available to help one in doing so. Transcribing Arabic-script manuscripts poses certain challenges right from the get-go, regardless of whether one is operating in a digital environment or not. Deciphering difficult handwriting, reconstructing lacunae caused by loss of material, navigating manuscripts with text running in multiple directions up and down along the page—the challenges of any paleographic endeavor, of course, vary in intensity from one manuscript to another or even within one single manuscript from page to page. It is easy in both digital and non-digital contexts to skip a line while transcribing, or to let other errors creep in—all part of the occupational hazards of medieval and early modern scribes! Digital environments introduce their own difficulties: resolution might not be as high as desired, viewing a page on the screen can feel cramped, and skipping or confusing lines becomes easier, particularly if one has an open PDF side-by-side with a word processor document. Different digitization formats can cause their own headaches, too. That said, working with manuscripts in a digital environment, while never a total replacement for physical access, has its own advantages, such as the ability to effortlessly zoom in (if the scan image resolution is good enough), to flip through many pages without fear of damaging them, to compare multiple manuscripts at once in a single viewing window, and so forth.
One such tool is the digital corpus production platform we at OpenITI have been using and helping to refine, eScriptorium. As the name suggests, it has manuscript transcription built into its digital DNA. Much of our work thus far has focused on print texts, using eScriptorium to segment and automatically transcribe texts for manual correction and inclusion in training data sets. We have also been working on manuscripts, which will feature prominently in the next phase of our work. While eScriptorium cannot be used for everything when it comes to digital manuscript work, it is very good for transcription and has potential for other forms of use as a digital paleography tool. In what follows here I want to first go over the basic process of using eScriptorium for manuscript transcription, followed by a short discussion of the advantages eScriptorium brings to the table when it comes to manuscript transcription. Finally, I will highlight some areas in which eScriptorium has further potential, which we hope to realize in coming months through our own work and through community participation. Towards that end, I will be hosting a relatively informal paleography and transcription working group over the course of this summer. Participants will be given access to eScriptorium, and we will meet every other week or so to discuss the manuscripts we are working on, resolve paleographic issues, and troubleshoot transcription and digital work problems. For anyone reading this who is interested in participation, please email me at jallen22@umd.edu; participation is strictly voluntary and individuals are free to join and drop out at any time. We’d love to use any transcriptions you produce as training data, but the choice is yours whether to share or not.
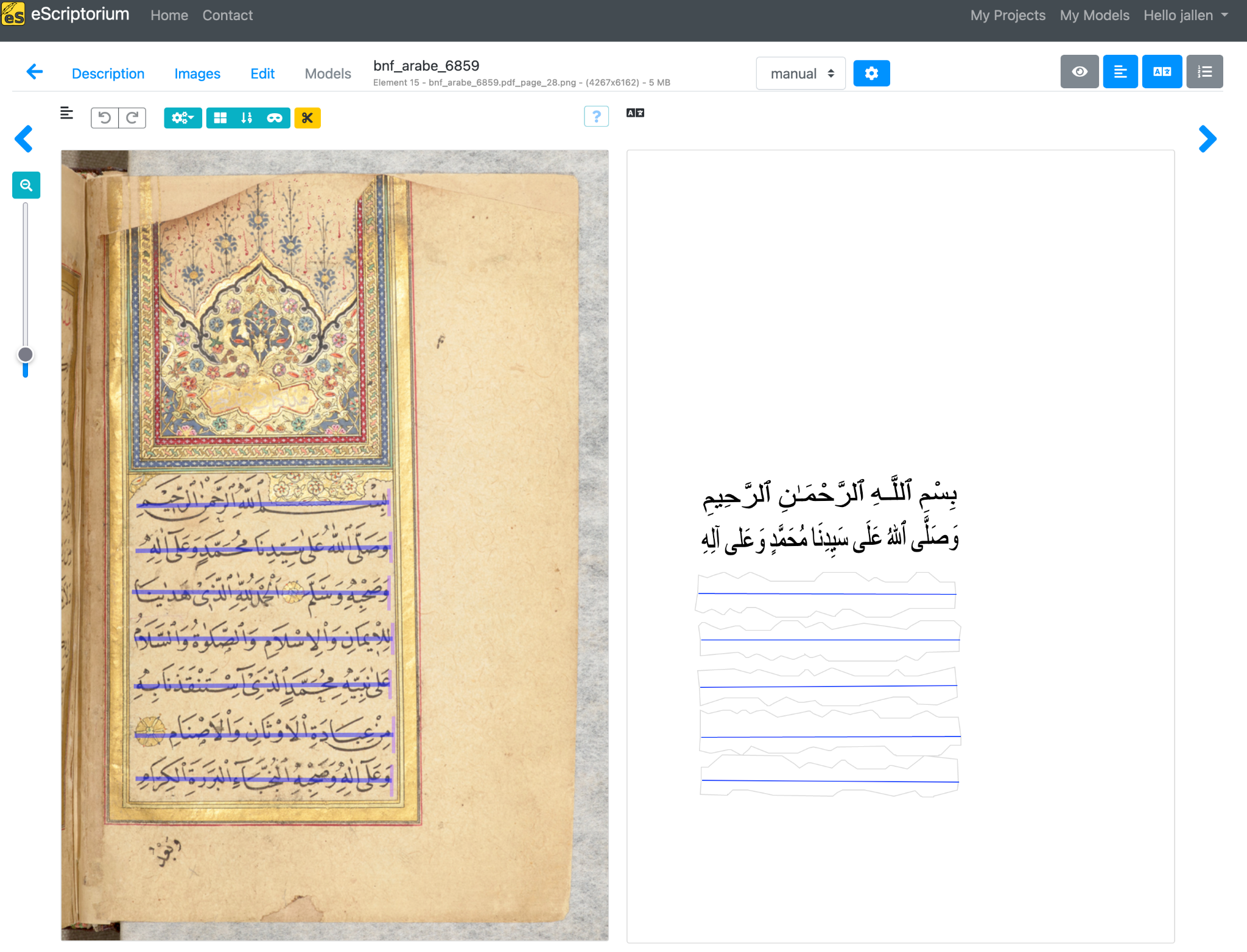
Alright, let’s do a quick walk-through of eScriptorium with an eye to manuscript transcription. First off, you of course need a digitized manuscript. We won’t go into how you find those here, though that is no doubt a topic we should cover in this space. You’ll find that digitized manuscripts typically are available in either PDF format and/or as individual image files, usually JPEG or TIFF. Some repositories give you the option of both PDF download and bulk image download, while a few only offer individual images (which if you’re savvy in such things you could scrape). Some repositories also offer IIIF as an option. All of these options are supported by eScriptorium: if you have individual images you can drag and drop them into the box on the “Images” tab:
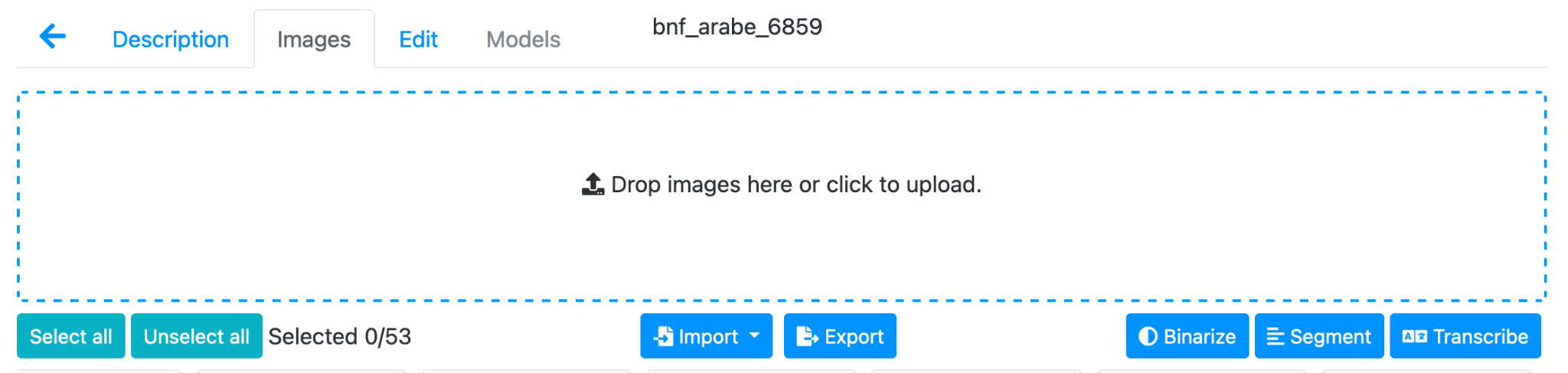 Fig. 1: A screenshot from eScriptorium showing the ‘Images’ tab of a document.
Fig. 1: A screenshot from eScriptorium showing the ‘Images’ tab of a document.
You can upload PDFs and IIIF manifests by clicking the “Import” button:
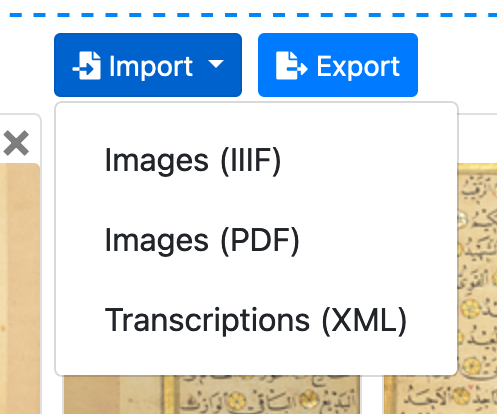 Fig. 2: A screenshot from eScriptorium showing the ‘Import’ button, located below the drag and drop box under the ‘Images’ tab.
Fig. 2: A screenshot from eScriptorium showing the ‘Import’ button, located below the drag and drop box under the ‘Images’ tab.
In both cases, individual pages will be disaggregated into single images; if your digitized manuscript has been scanned with two pages facing in one PDF page, you may want to consider automatically splitting the pages before uploading the file to eScriptorium.It makes life easier for everyone.
From here on out, unless you’ve generated your own models for a specific manuscript or hand, you’ll want to stick to manual segmentation and transcription. First, you can segment the lines in your manuscript; there are many options for doing so. You may simply draw a straight line across by clicking once and pulling a straight line across to the other end (make sure to go left to right when doing this). You might also try to freehand your line along the actual baseline as best you can. This latter option will be necessary for lines that move about on the page.
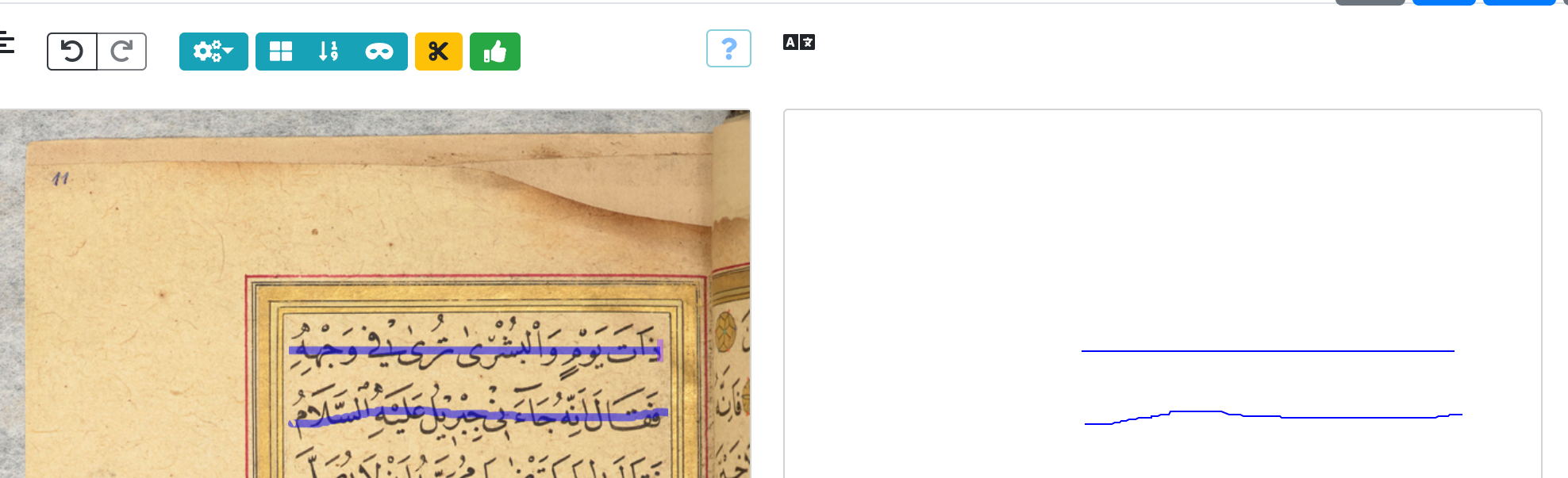 Fig. 3: A screenshot from the transcription editing page on eScriptorium. A green thumbs-up icon is featured left of the top middle portion of the image.
Fig. 3: A screenshot from the transcription editing page on eScriptorium. A green thumbs-up icon is featured left of the top middle portion of the image.
After you’ve drawn your lines, click that green thumbs-up icon on the left, and this will generate the masking for each line, the space within which the characters appear:
 Fig. 4: A screenshot demonstrating a manuscript image with transcription lines and masks over it, as well as a separate image consisting solely of lines and masks with no manuscript referent shown.
Fig. 4: A screenshot demonstrating a manuscript image with transcription lines and masks over it, as well as a separate image consisting solely of lines and masks with no manuscript referent shown.
As you can see, you may need to modify the masks somewhat to fully capture all of the characters and the vowels, though if you are not contributing your transcription to a training data set this is not necessarily required. You can shift the masks by clicking on the lines and dragging them about; it’s not at present the easiest process but it can be made to work with some practice.
Once you’re happy with the segmentation you can begin transcribing. Simply click on one of the lines on the right, and the following will appear, ready for you to enter your text:
 Fig. 5: A screenshot from the manual transcription window of eScriptorium. There is handwritten Arabic text above a blank white rectangle.
Fig. 5: A screenshot from the manual transcription window of eScriptorium. There is handwritten Arabic text above a blank white rectangle.
There are other features of eScriptorium applicable to manuscript transcription and digital paleographic work. You can designate specific regions of text (main, marginalia, etc) as well as specific lines (poetry, interlinear, running titles). This can be useful for a number of purposes, such as only extracting marginal materials or main text, as well as for more advanced techniques that use some form of internal tagging. Once you’re done with your transcription, you have a range of options for export: plain text, ALTO, and PageXML. While you transcribe your text, you can leave notes internal to it, tag rubrication, damage, or any other features you might want to include for a traditional critical edition. eScriptorium also permits zoom, though for now you’re probably better off keeping a PDF open if you need high resolution.
Why might you want to use eScriptorium for manuscript transcription? Well, for one thing it’s free.You can both manually transcribe documents and refine your own models for segmentation and transcription using self-generated training data. In the future, robust models for handwritten text recognition in the Arabic script tradition will be available, which could open up many new possibilities.
The line-by-line feature is probably the single most powerful aspect of the platform for manuscript transcription. Not only does it zoom in on the text, it keeps each line separate sight-wise from the others. It also proceeds consecutively, which means you’re far less likely to skip lines or mix them up. You can edit documents by yourself or share them with others for review. Export is easy, and you can include any number of notes or systematic annotations within the transcription line. There are also possibilities for the more tech-savvy in the XML modes of export (which can include image export, useful if your source was a PDF or IIIF import). Moving through pages and up and down them is straightforward and intuitive.
There is still room for expansion in how we use eScriptorium for manuscript transcription. I have only just touched on regions annotation—while we have developed a solid system for print transcription, manuscripts pose their own unique challenges given the sheer diversity of layouts and textual arrangements. Manuscript transcription conventions are also a real sticking issue. Simply put, there are more letterforms in the manuscript tradition than are represented by unicode characters available, and figuring out how to best reproduce everything in a systematic and normalizable manner is a work in progress.
Finally, as someone who has been using this platform for some time, both to generate print training data and increasingly for manuscript transcription, I can say that it is genuinely quite enjoyable to use most of the time. It is not the only way to interact with a manuscript digitally, as it works best at the line, word, and character level, not necessarily at the page level—though this is an area in which I think future iterations of eScriptorium might improve. For transcription, eScriptorium is an ideal platform and can be easily integrated into other ways of studying and interacting with digitized manuscripts, helping us to unlock the many treasures that still await within the vast repositories of Arabic script heritage.